For our final Data-X project, we teamed up with AnChain.ai, a Silicon Valley based blockchain security company, to identify features of a bot and create a machine learning model to identify bots in a blockchain environment.
Team Goals

The first objective as a team was to identify the characteristics of bots. We had as a group had to create a set of features for each bot account to identify which accounts are bots and train our machine learning model.
|

Our second object was to create different machine learning models to identify bots from our original dataset. We had to test different methods to find out which model best work for our project task.
|
Step One : Define Bot Features
Activity_day: How many days each account is active for transactions in one month
Active_hour: How many hours each account is active for transactions per day
Active_hour_len: How many continuous hours account is active for transactions per day
Max_Active_hour: How many hours each account is active for transactions in unit period
Max_Active_hour_len: How many continuous hours account is active for transactions in unit period
Transaction level: Total number orders for each customer
Time_interval_rate: Highest active time interval rate: The higher the rate, the more likely to follow some fixed active pattern.
Frequency_variance: Variance of total number orders for each customer per day
Quantity_variance: variance of transaction quantity for each customer per day
num_account_type: the number of types of “account” count
type _d_unit: the number of types of “d_quantity_unit” count - what type of token you would use for a game
Active_hour: How many hours each account is active for transactions per day
Active_hour_len: How many continuous hours account is active for transactions per day
Max_Active_hour: How many hours each account is active for transactions in unit period
Max_Active_hour_len: How many continuous hours account is active for transactions in unit period
Transaction level: Total number orders for each customer
Time_interval_rate: Highest active time interval rate: The higher the rate, the more likely to follow some fixed active pattern.
Frequency_variance: Variance of total number orders for each customer per day
Quantity_variance: variance of transaction quantity for each customer per day
num_account_type: the number of types of “account” count
type _d_unit: the number of types of “d_quantity_unit” count - what type of token you would use for a game
Step Two : Cleaning Dataset + Adding Features to AnChain.ai dataset
- We were given 10 bot accounts and 10 human accounts, tasked with assigning the rest of our dataset and adding features
Original Dataset

New Dataset + Feature set
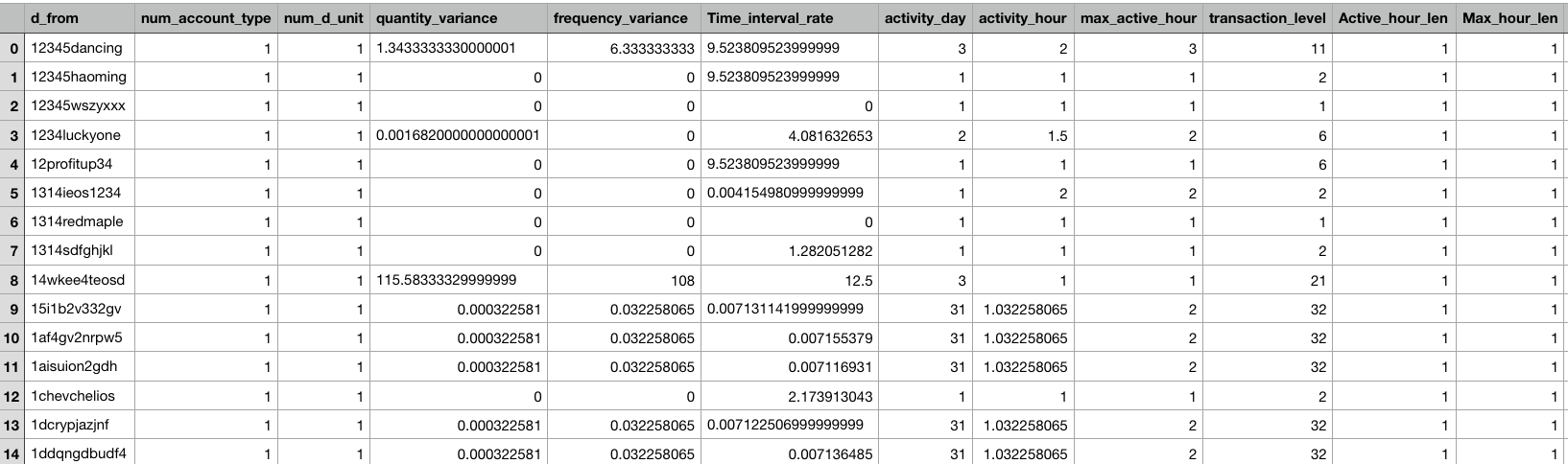
Step Three (First Scrum) : Manually label 400 accounts
|
Human Account
|
Bot Account
|
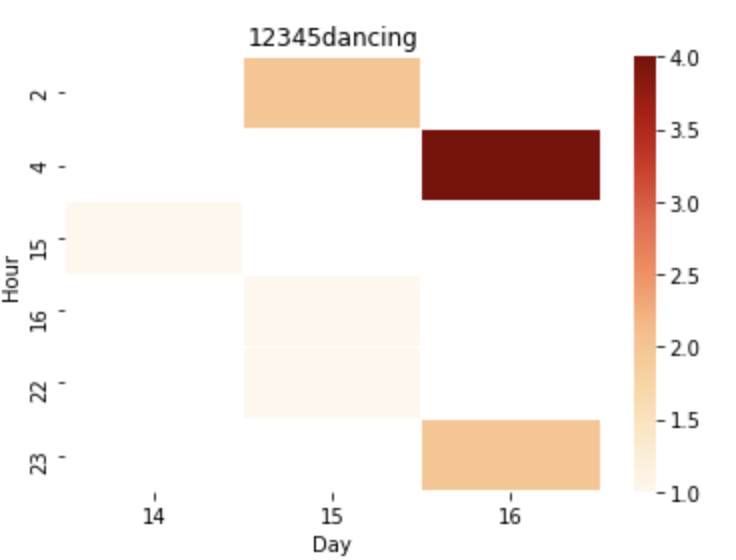
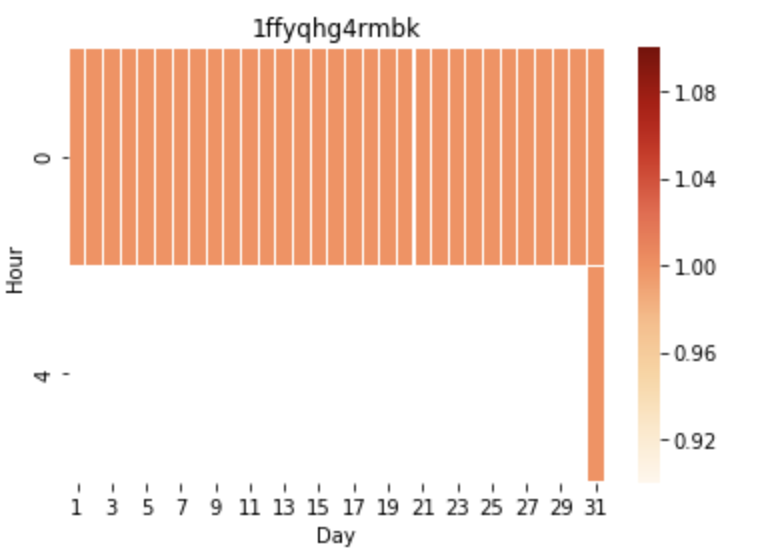
Characteristics of a Bot
-Consistent frequency
-Same time everyday
-Same quantity everyday
-Similar duration
-Consistent frequency
-Same time everyday
-Same quantity everyday
-Similar duration
Step Four : Under-sampling and creating our Logistic Regression Model
- In order to label the rest of our dataset, we under sampled our bot accounts for our LR model, because we did not want to bias the machine learning model.
- Trained the LR model and gave each account a probability distribution. 0 meaning it is a human, 1 being that the account is a Bot.
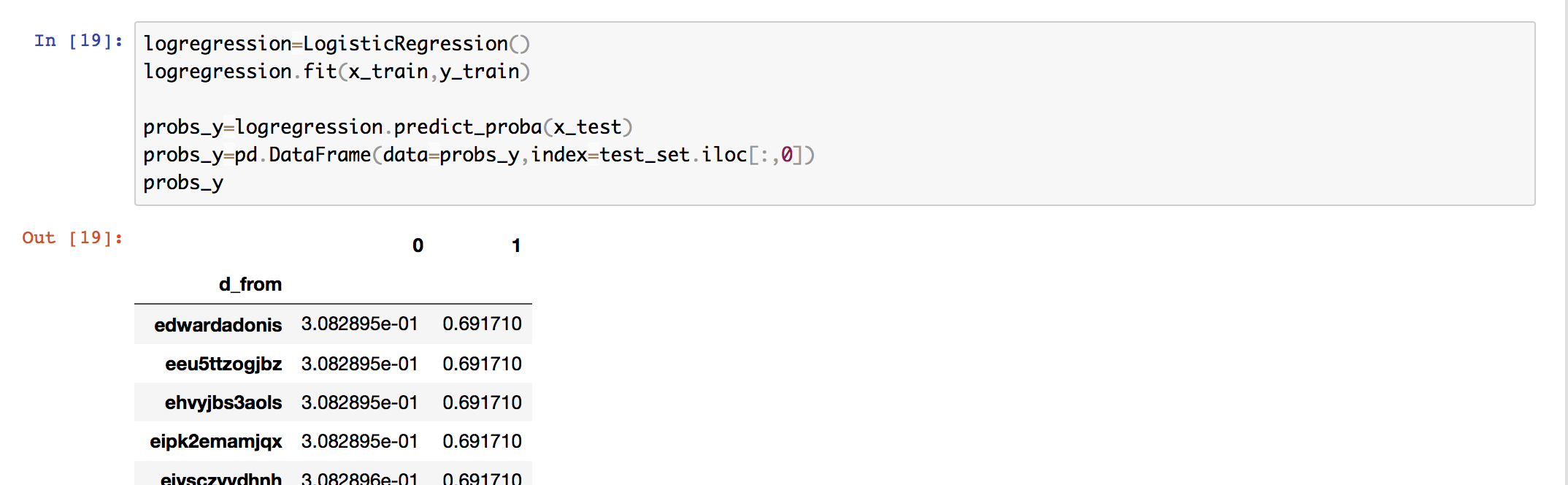
Insights
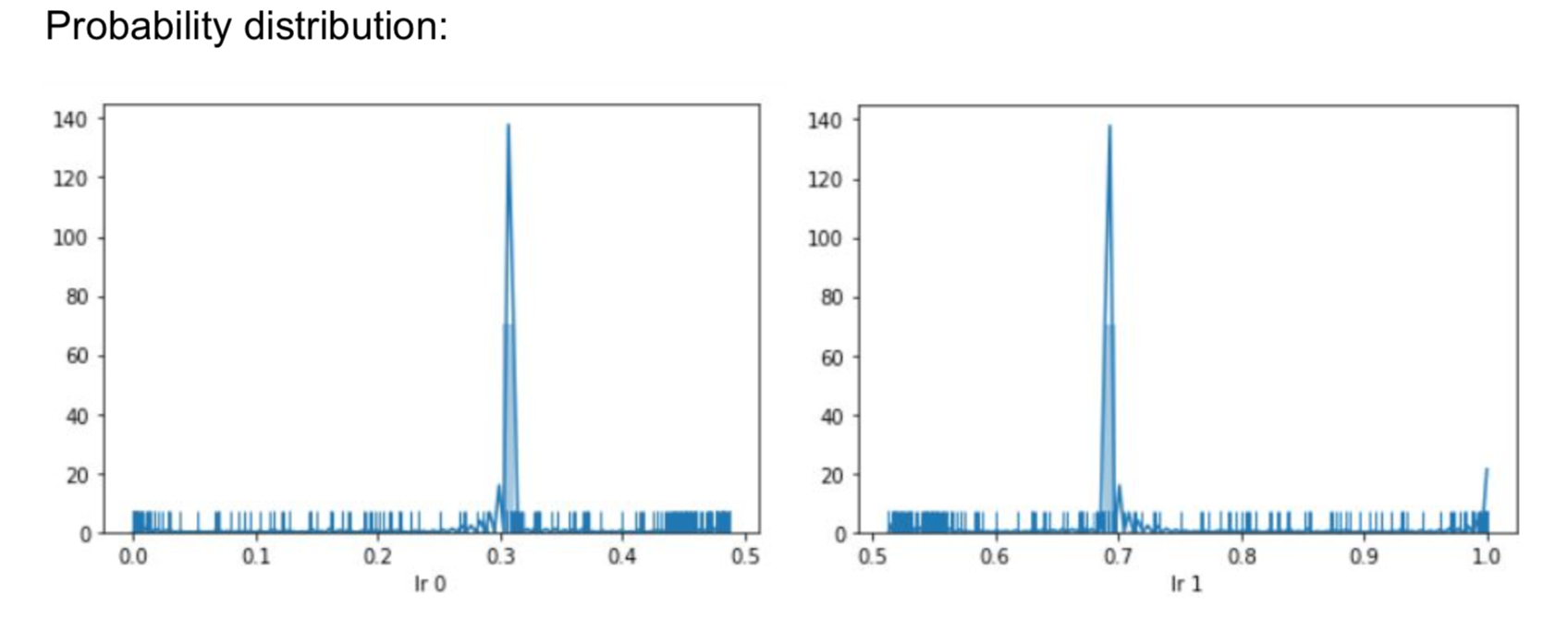
- We noticed that the human accounts hovered around .3 were as the bot accounts mode was around .7
- Set out LR to label an account 0 or Bot if it's probability distribution was >.65
- We were left with 95, default or unknown, accounts after this
- Finally manually labeled rest of the dataset
More Heat-maps to Analyze...
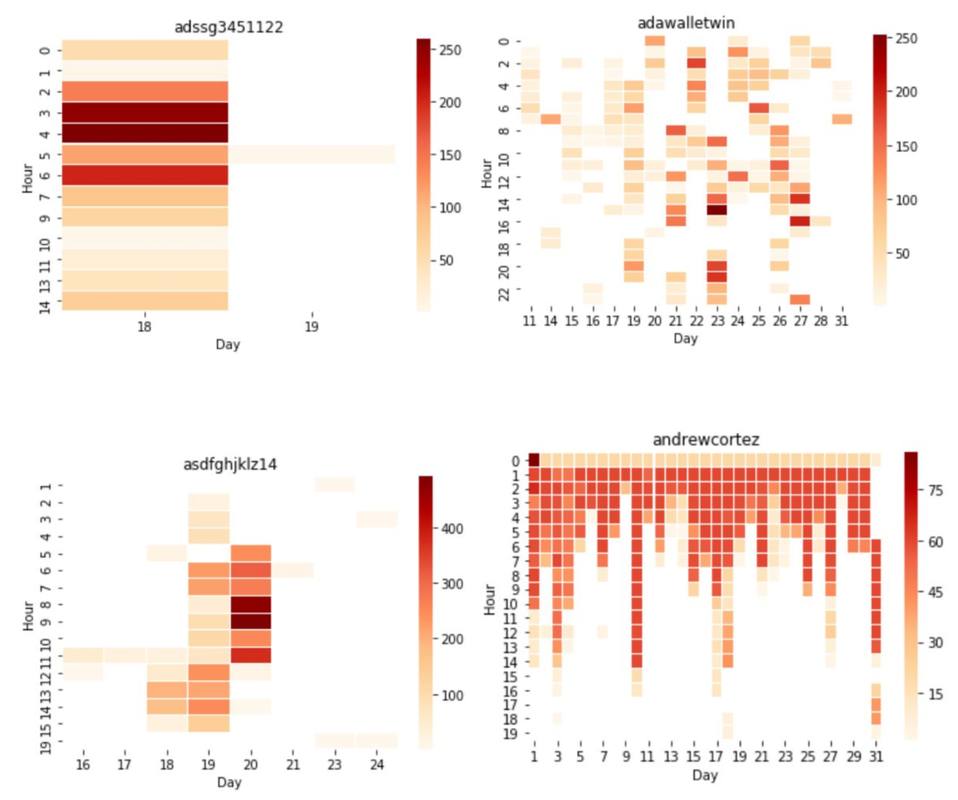
Final Dataset Description

Trained Machine Learning Models
Created Training Set + Test Set

4 Different Models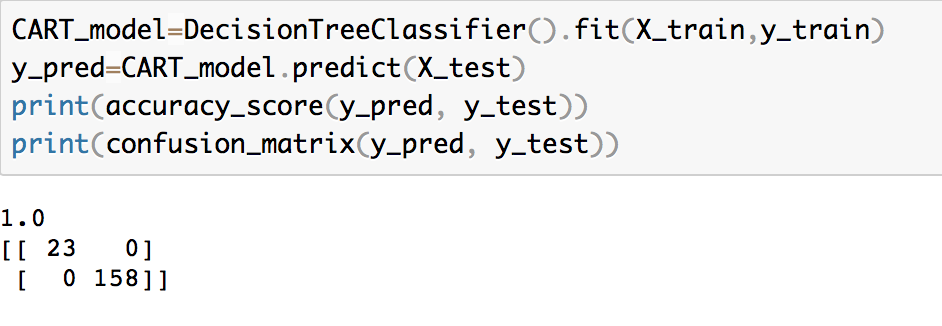
|
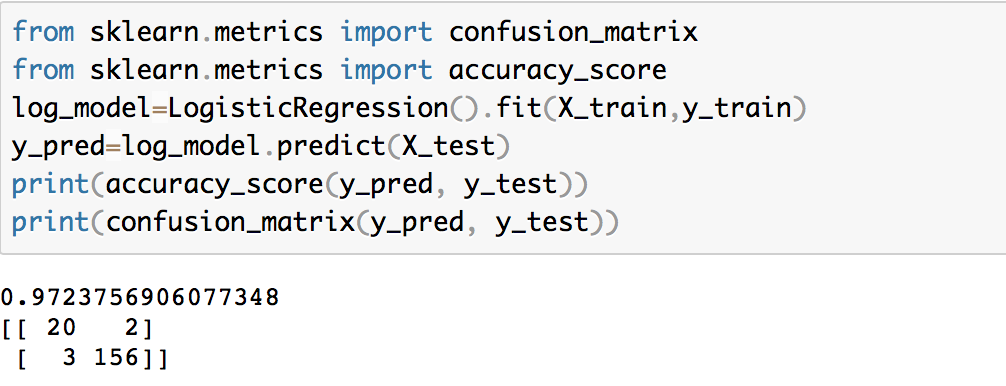
|
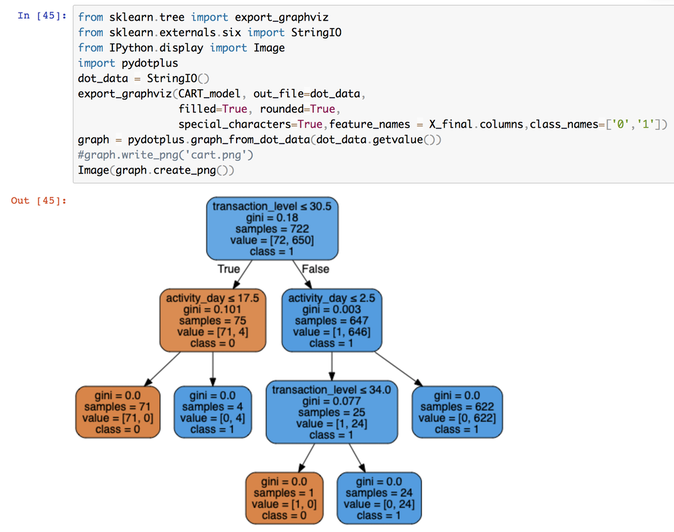

|
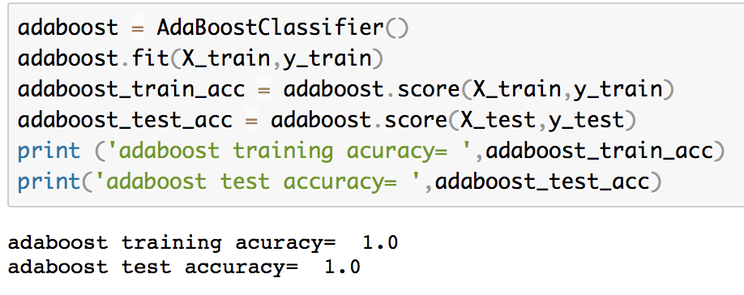
|
Test Feature Importance Using Random Forest Model
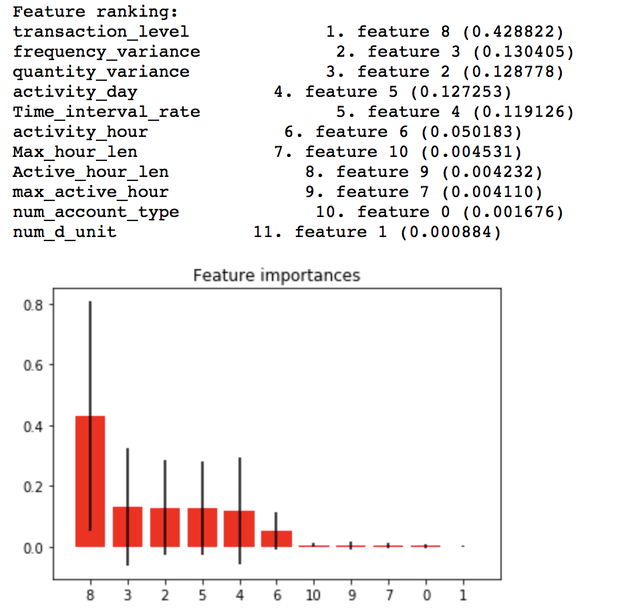
Conclusion
- Feature Engineering
Original datasets are hard to train a model on, we need to use common sense to extract the most useful features for model building.
- Model Selection
Different models have their own pros and cons, find the most suitable models for the problem is important.
- Bias of Manual Labeling
Supervised learning requires human labeling, which is a big work. However, it might cause bias, especially facing human behavior indication.
Original datasets are hard to train a model on, we need to use common sense to extract the most useful features for model building.
- Model Selection
Different models have their own pros and cons, find the most suitable models for the problem is important.
- Bias of Manual Labeling
Supervised learning requires human labeling, which is a big work. However, it might cause bias, especially facing human behavior indication.
